

Windows 11 comes with new features and a fresh look, and with a redesigned Start menu. If you don’t want to get used the new design, you can go back to the classic Start menu look like in Windows 7.
How to Restore Windows 7 Start Menu
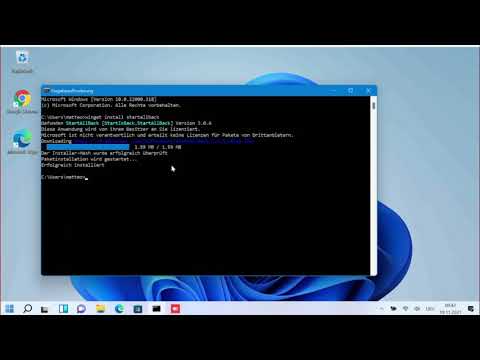
Hit the Windows-Logo key, or click on Start and type in cmd they will open command prompt, here you paste the following command and hit enter.
winget install startallbackAt the first run, the confirmation of the license terms is asked, which you accept by pressing the Y button.
If you want to go back to the Windows 11 Start menu, simply hit uninstall the tool.
winget uninstall startallbackAddendum
The Start menu is a graphical user interface element that has been part of Microsoft Windows since Windows 95, providing a means of opening programs and performing other functions in the Windows shell.
Start menu, and the Taskbar on which it appears, were created and named in 1993 by Daniel Oran, a program manager at Microsoft who had previously collaborated on great ape language research with the behavioral psychologist at Harvard.
The Start menu was renamed Start screen in Windows 8, before returning to its original name with Windows 10.
It has been co-opted by some operating systems (like ReactOS) and Linux desktop environments for providing a more Windows-like experience, and as such is, for example, present in KDE, with the name of Kickoff Application Launcher, and on Xfce with the name of Whisker Menu.
Traditionally, the Start menu provided a customizable nested list of programs for the user to launch, as well as a list of most recently opened documents, a way to find files and obtain assistance, and access to the system settings.
Later enhancements via Windows Desktop Update included access to special folders such as “My Documents” and “Favorites” (browser bookmarks).
Windows XP’s Start menu was expanded to encompass various My Documents folders (including My Music and My Pictures), and transplanted other items like My Computer and My Network Places from the Windows desktop. Until Windows Vista, the Start menu was constantly expanded across the screen as the user navigated through its cascading sub-menus.

